ハローの@satoakickです。 普段はRespoという飲食店向け業務支援Saasのバックエンドを担当しています。
Respoは、予約管理、セルフオーダー、POSレジ、テイクアウト対応など、飲食店の業務効率化を支援する多機能なプラットフォームです。
PostgreSQLなどのRDBMSを使ってサービスを運用していると、思いもよらないクエリのパフォーマンス劣化に遭遇することがあります。 今回はその中でも「LEFT JOIN + IS NULL」構文の落とし穴と、 NOT EXISTSによる劇的な改善事例を紹介します。
DBの監視
ハローではDBの状態をGCPのアラートポリシーで異常検知や隔週でQuery Insights状況のリマインドをSlackに通知されるように設定し、日頃からパフォーマンスには目を光らせるようにしており、何か異常があればオンコール担当者がGCPのQuery Insightsを使って原因を特定し、都度対応しています。
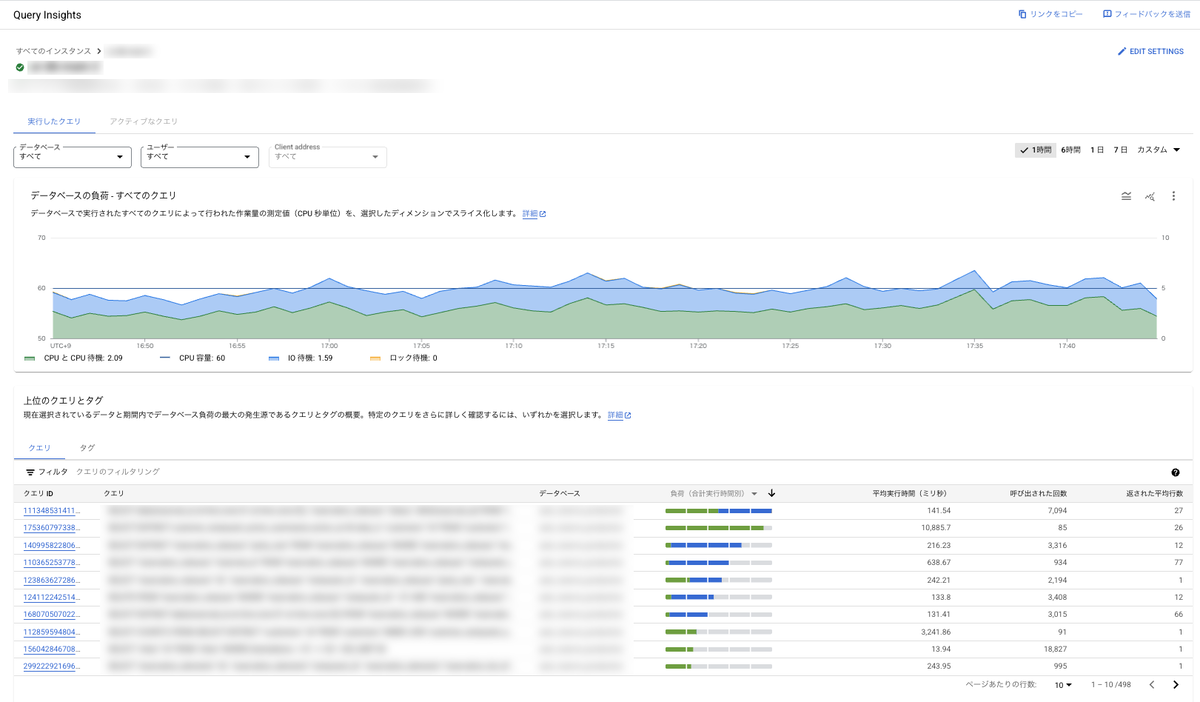
Query Insightsはクエリプランなども参照できるのでパフォーマンスチェックには欠かせない情報をいい感じに可視化してくれるので重宝します。
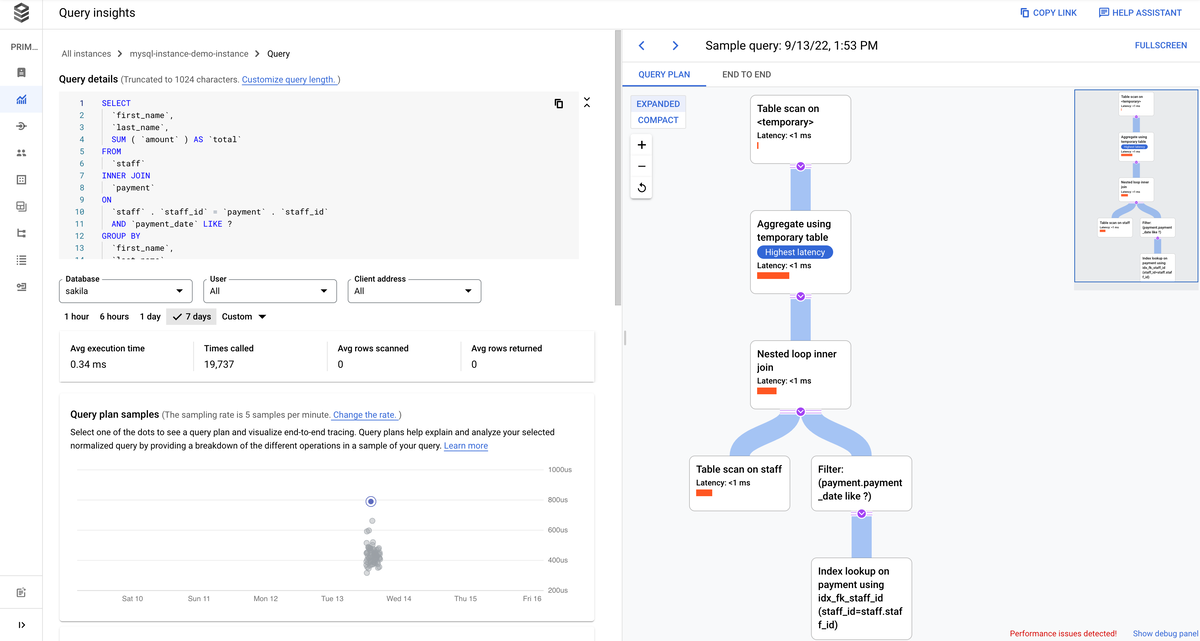
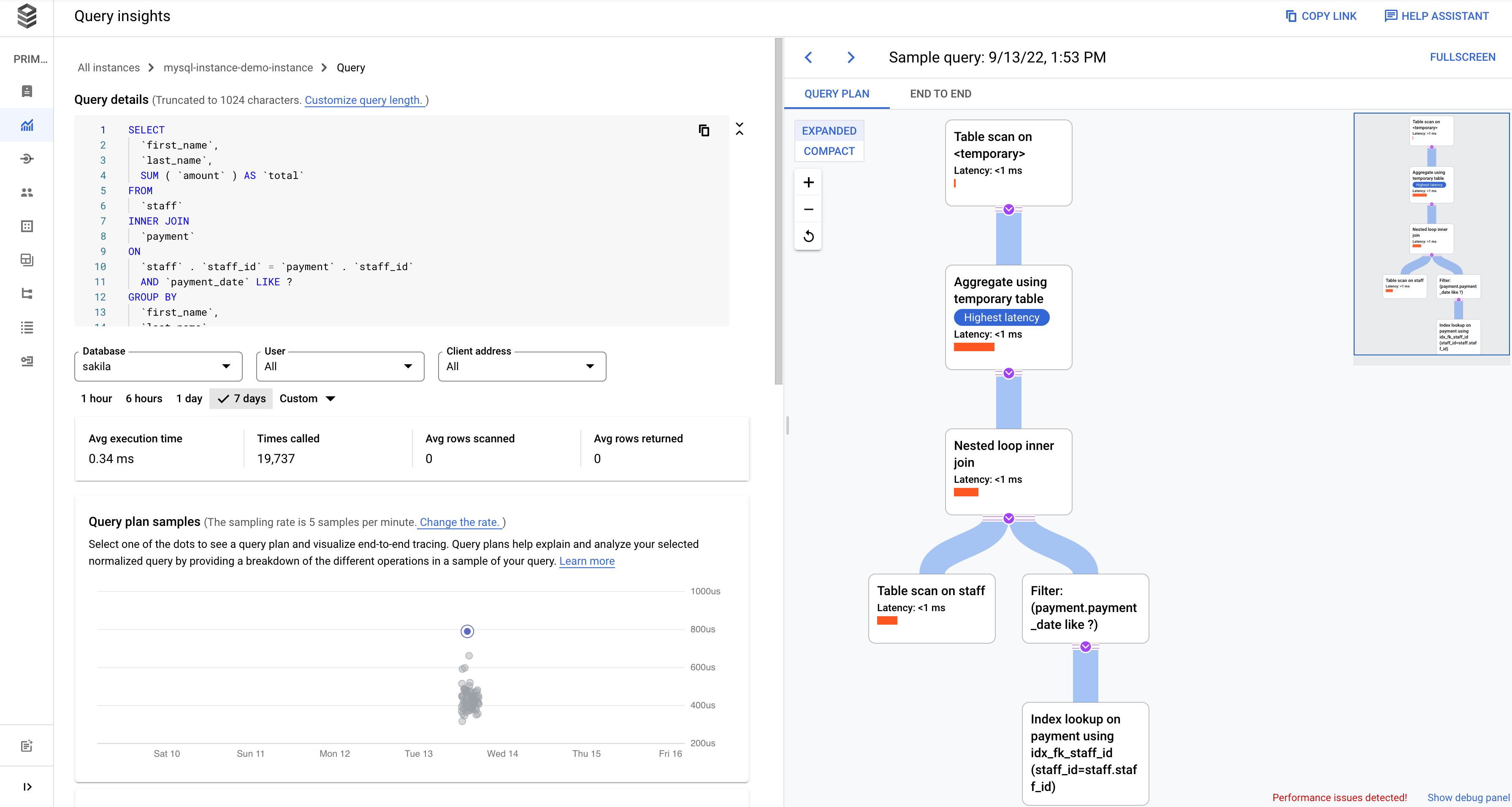{kind=link}
チューニング対象のクエリ
クエリチューニングは「インデックスの貼り忘れ」や「N+1問題」が原因であることが多く、それらを直せば解決することも多いです。 しかし今回は、それらでは解決しないケースでした。
ある日、DBのCPUアラートが監視専用チャンネルに飛んできたので、上記のような対応で解消すればいいだろうと思い、Query Insightを参考にクエリの形から呼び出し元のコードを特定したところ、以下のような形のコードでした。
A.left_joins(:b).where(hoge: fuga).where(bs: { id: nil })
このクエリはwhere句の条件を外すと、
explain analyze SELECT "A".* FROM "A" LEFT OUTER JOIN "B" ON "B"."a_id" = "A"."id" WHERE "B"."id" IS NULL ORDER BY "A"."id" ASC LIMIT 1000
というSQLで、なんの変哲もないjoinだったのですが、実行計画をみると数十万〜百万のレコード同士のleft joinで盛大にseq scanが走っていました
Limit (cost=1544076.63..1544076.64 rows=1 width=1062) (actual time=4716.771..5126.862 rows=1000 loops=1) -> Sort (cost=1544076.63..1544076.64 rows=1 width=1062) (actual time=4716.770..5126.792 rows=1000 loops=1) Sort Key: A.id Sort Method: top-N heapsort Memory: 1523kB -> Gather (cost=66032.48..1544076.62 rows=1 width=1062) (actual time=2749.125..4338.104 rows=2133978 loops=1) Workers Planned: 2 Workers Launched: 2 -> Parallel Hash Left Join (cost=65032.48..1543076.52 rows=1 width=1062) (actual time=2750.071..3775.592 rows=711326 loops=3) Hash Cond: (A.id = B.a_id) Filter: (B.id IS NULL) Rows Removed by Filter: 201687 -> Parallel Seq Scan on A (cost=0.00..1029230.80 rows=1666380 width=1062) (actual time=0.013..1124.265 rows=913013 loops=3) -> Parallel Hash (cost=59378.88..59378.88 rows=307888 width=24) (actual time=89.454..89.455 rows=201687 loops=3) Buckets: 65536 Batches: 16 Memory Usage: 2656kB -> Parallel Seq Scan on B (cost=0.00..59378.88 rows=307888 width=24) (actual time=0.006..51.080 rows=201687 loops=3) Planning Time: 2.173 ms Execution Time: 5127.078 ms
このクエリは定期バッチから実行され、日に何度も実行されていました。
レコード数が数十万から数百万あるテーブル同士のjoinなので少なくともインデックスによる効率化は狙いたいところです。
a_idにはすでにインデックスがついているのにも関わらず、IS NULL条件が影響しているのか、インデックスが効いていませんでした。さらにjoinのアルゴリズムとしてHash joinが選択されています。
Hash JoinはjoinのアルゴリズムのNested loopsに比べ、ハッシュテーブル構築時にメモリを消費しますが、この時メモリに収まらない場合はディスクに一時的に書き出され、ディスクI/Oが発生して処理速度が著しく低下してしまいます。
一般にメモリのアクセススピード >> ディスクアクセススピードなのでデータ量が多いクエリでは注意を要します。
特にPostgreSQLではwork_memの設定した値よりも多くのメモリが消費されると、一時ファイルへのI/Oが起こり、上記の理由により急激なパフォーマンス劣化が発生してしまうので、積極的には利用してほしくはありません。
さらに全件JOINしてからfilter条件として後から不要なデータを除去しているため非効率なクエリと言わざるを得ません。
改善結果
今回のクエリがやりたいことはジョインしてBが存在しないものを取得したいだけなので、これはNOT EXISTS句が使い所では?と考え、 NOT EXISTS句を利用して実行計画が改善するか試してみたところ、
EXPLAIN ANALYZE SELECT "A".* FROM "A" WHERE NOT EXISTS ( SELECT 1 FROM "B" WHERE "B"."a_id" = "A"."id" ) ORDER BY "A"."id" ASC LIMIT 1000;
Limit (cost=1.05..1335.58 rows=1000 width=1062) (actual time=0.428..16.976 rows=1000 loops=1) -> Merge Anti Join (cost=1.05..4289696.57 rows=3214373 width=1062) (actual time=0.427..16.892 rows=1000 loops=1) Merge Cond: (A.id = B.a_id) -> Index Scan using A_pkey on A (cost=0.43..4248908.28 rows=3953304 width=1062) (actual time=0.035..15.600 rows=3035 loops=1) -> Index Only Scan using index_B_on_a_id on B (cost=0.42..21668.39 rows=738931 width=8) (actual time=0.005..0.617 rows=2036 loops=1) Heap Fetches: 245 Planning Time: 0.290 ms Execution Time: 17.059 ms
いい感じに改善できました。ちゃんとインデックスも効いています。実行時間は最終的に修正したコードで計測したところ、およそ30倍の改善となりました。
NOT EXISTS句を利用したことでanti join(結合条件にマッチしないレコードを取得するための特殊なJOIN)を利用しつつ、さらにseq scanの代わりにインデックスが走ってくれるようになりました。
joinのループにおいて anti joinは存在すれば処理を打ち切るため、余計なループが減ってインデックスが利用され、大幅なパフォーマンス改善ができました。*1
NOT EXISTS句の存在は知っていたのですが、これまでクエリパフォーマンスのために利用したことがなかったので、とてもいい経験になりました。
We are hiring!
ハローでは、クエリチューニングやテーブル設計に興味のあるバックエンドエンジニアを絶賛募集中です!
*1:今回のPostgreSQLのバージョンは14です。未調査ですが、より新しいバージョンのPostgreSQLではleft join + is NULLでもanti joinを利用するようになっているかもしれません